In Part 1 of this series, I was complaining that we rarely draw the line between the development and performance teams, divvying up the responsibilities for making the system perform. Who's going to do which parts? When the developers do nothing, we end up something real similar to the spectacular failure of the healthcare.gov launch. When developers do too much, we risk premature optimization.
But before we can assign tasks to groups, we need to decide on the list of tasks. Does such a list exist? Let me tell you a quick story about me getting grilled by a 'new sheriff in town' performance manager.
I switched from java development to performance tuning in 2006. Once of my first performance managers had come from the functional QA side of the house and he immediately took me off guard. "How can we train performance engineers if you all don't even have a plan to begin with?", he asked me. I was a little stunned. blink. blink. I was just asking for a training budget and he wanted to question my credentials. He was skeptical that performance people had any clue what they were doing, and was eager to put me on the spot, and I had just enough doubt to question myself. Do we really have a repeatable game plan for delivering well performing applications into production?
Several years later after a lot more performance work, I can report that that notion is silly, that we don't know what kills performance. The performance teams I've led over the last 8 years have become board stiff (bored but overworked, actually -- not a good combination). We bolt the monitoring tools onto the applications and look under the covers. What we see is mostly the same boring, preventable problems on the list, year after year (here are 3 big hitters on my list). Perhaps your list is completely different than our list.
I'm good if your list and my list are different -- I just think all projects need to establish _some_ list of performance anti-patterns to be avoided, and someone needs to assign throats-to-choke to each item on the list. Do your development teams do this? Are performance considerations even included in design?
Assembling this magic list is not an easy task. Don't have time right now, but I need to finish my blog entry about which group is best suited for various tasks. Part 3.
Also unfinished is an entry about how I kinda crashed and burned with my first two attempts to get development teams to work with a list. Hopefully you can learn from these mis-steps which will be Part 4.
Sunday, October 19, 2014
Saturday, October 18, 2014
Part 1: A Forbidden Discussion in Software Development
As a performance engineer, I feel a bit tarnished after the launch failure of healthcare.gov. I was in no way involved and those responsible do not own the monopoly on launch failures. But from the outside, does it really look like we know what we're doing, like we have a 'big plan?'
One thing missing from such a 'big plan' is a discussion of who is responsible for specific tasks for ensuring system performance. We have not drawn a line for ourselves and said whether the development team or the performance tuning team is responsible for various tasks, like these:
One thing missing from such a 'big plan' is a discussion of who is responsible for specific tasks for ensuring system performance. We have not drawn a line for ourselves and said whether the development team or the performance tuning team is responsible for various tasks, like these:
- Who validates that the SQL queries hit the right indexes ? (sorry, I can't do "indices")
- Who makes sure the static data in database is cached, keeping us from fetching to death those little bits of rarely-changing data.
- Who keeps the SELECT N+1 anti-pattern out of the code base?
And I'm just getting started, the list goes on: pagination for long lists, memory leak detection, CPU profiling, setting throughput goals. Which team is going to tackle these? Dev or performance? We need to draw the line and explicitly say who owns what. We need to start talking about this.
I have seen dozens of development teams, in the company I work for and elsewhere, that resist being tasked with performance concerns. Why is this? Do we deeply yearn to be blind folded and in plaid pajamas, spewing crappy performing code that functions beautifully? If that is true, we also delight in defending these plaid pajamas not out of laziness or negligence, but out of the most noble intentions: avoiding premature optimization. I'm a java architect as well as a performance engineer and I'm at times guilty of this over-zealotry, too.
I feel obliged, at this point, to defend my cred as a performance engineer and put myself on the record. Wasting time on over-optimization is indeed a problem that deserves considerable concern, like setting and sticking to your performance goals. But as an industry, to the peril of the likes of healthcare.gov, we have failed to define the middle ground, to flesh out design & development's share of the responsibility for performance. The discussion to divvy out these chores seems oddly forbidden.
I have seen dozens of development teams, in the company I work for and elsewhere, that resist being tasked with performance concerns. Why is this? Do we deeply yearn to be blind folded and in plaid pajamas, spewing crappy performing code that functions beautifully? If that is true, we also delight in defending these plaid pajamas not out of laziness or negligence, but out of the most noble intentions: avoiding premature optimization. I'm a java architect as well as a performance engineer and I'm at times guilty of this over-zealotry, too.
I feel obliged, at this point, to defend my cred as a performance engineer and put myself on the record. Wasting time on over-optimization is indeed a problem that deserves considerable concern, like setting and sticking to your performance goals. But as an industry, to the peril of the likes of healthcare.gov, we have failed to define the middle ground, to flesh out design & development's share of the responsibility for performance. The discussion to divvy out these chores seems oddly forbidden.
Before we draw the line, before we decide who's responsible for 'what', we first need to agree on the 'what' part. Does a short-list really exist -- a list of performance anti-patterns that should be avoided in most cases? If not, then perhaps we don't have a 'big plan', after all.
Keep reading here for part 2.
Keep reading here for part 2.
Chatty SQL Performance Anti-Patterns
Year after year, these three SQL "data access" anti-patterns cause a large percentage of the performance problems we see as performance engineers.
Anti Pattern 1: "SELECT N+1"
ANTI-PATTERN: When code, instead of joining two tables, iterates through the result set of the parent table and executes
SELECTs to the child table. Much has been written on this topic.
TO REFACTOR (Option 1): Join the parent and child tables. Here is one way to tackle this with Hibernate, if the # of rows is reasonable small enough (perhaps < 200) to be retrieved in one trip.
If more than 200 rows are to be returned, consider using hibernate batch size parameter.
If more than 200 rows are to be returned, consider using hibernate batch size parameter.
TO REFACTOR (Option 2): Instead of JOINing, use a sub-select, like this:
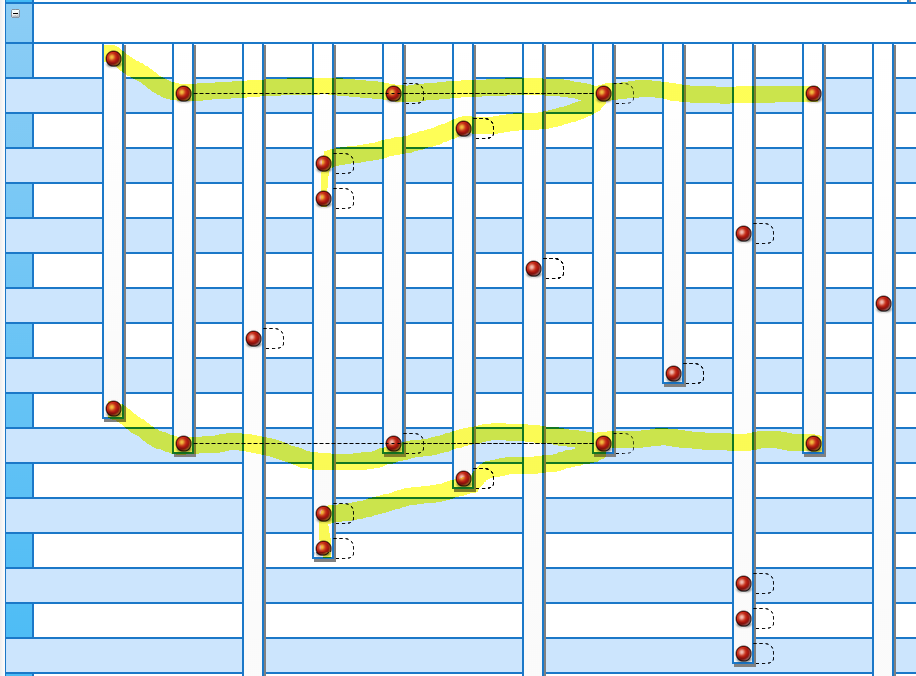
This describes the relationship between just two tables. Often we see a parent table driving the results of an entire pattern of table accesses. Instead of SELECT N+1, we have SELECT N(x) +1, where (x) is the pattern of SQL statements instead of a single child table.
This diagram (from wuqiSpank) shows a pattern (in yellow) of SQL statements that is repeatedly executed.
{kind=link}
Anti Pattern 2: UnCached - Static
Static tables are those that generally get less than 1 update an hour during an average day of production traffic. All tables in a schema should be categorized as either static or dynamic, as seen here.
ANTI-PATTERN: Source code repeatedly
TO REFACTOR: Use EHCache (which includes Hibernate integration). The goal is to enable EHCache to essentially 'interrupt' the jdbc request and instead return results from an in-memory cache. EHCache manages a configurable cache refresh process.
ANTI-PATTERN: Source code repeatedly
SELECTs static data, even though that data rarely changes.TO REFACTOR: Use EHCache (which includes Hibernate integration). The goal is to enable EHCache to essentially 'interrupt' the jdbc request and instead return results from an in-memory cache. EHCache manages a configurable cache refresh process.
Anti Pattern 3: UnCached - Dynamic
ANTI-PATTERN: Source code retrieves dynamic data (perhaps customer or account data) from db and re-queries that same data before the business process has completed.
TO REFACTOR: Temporarily store the initial query results so they are available to subsequent code. For example, say that two web service calls are made after a user clicks a button. Both calls require the same five SQL queries for initialization. Solution: Refactor code into a single web service call instead of two.
TO REFACTOR: Temporarily store the initial query results so they are available to subsequent code. For example, say that two web service calls are made after a user clicks a button. Both calls require the same five SQL queries for initialization. Solution: Refactor code into a single web service call instead of two.
References
The following show that "SELECT N+1" is a widely problematic.
http://thecuttingledge.com/?p=169
http://ayende.com/blog/1328/combating-the-select-n-1-problem-in-nhibernate
http://pramatr.wordpress.com/2009/02/05/sql-n-1-selects-explained/
http://docs.telerik.com/data-access/developers-guide/profiling-and-tuning/profiler-and-tuning-advisor/data-access-profiler-n-plus-one-problem
http://www.hibernatingrhinos.com/products/nhprof/learn/alert/selectnplusone
http://www.pbell.com/index.cfm/2006/9/17/Understanding-the-n1-query-problem
http://dotnet.dzone.com/news/select-n1-problem-%E2%80%93-how
http://ayende.com/blog/1328/combating-the-select-n-1-problem-in-nhibernate
http://pramatr.wordpress.com/2009/02/05/sql-n-1-selects-explained/
http://docs.telerik.com/data-access/developers-guide/profiling-and-tuning/profiler-and-tuning-advisor/data-access-profiler-n-plus-one-problem
http://www.hibernatingrhinos.com/products/nhprof/learn/alert/selectnplusone
http://www.pbell.com/index.cfm/2006/9/17/Understanding-the-n1-query-problem
http://dotnet.dzone.com/news/select-n1-problem-%E2%80%93-how
Sunday, October 12, 2014
Chunky Outperforms Chatty
This repo on github contains Java code and results from a performance comparison of 5 different SQL data access strategies, ranging from very chatty to very chunky.
- Chatty = many SQL invocations that touch relatively few records.
- Chunky = fewer SQL invocations that touch more records.
The two chunkiest strategies (1 & 2) outperform the rest, with roughly 30% or more tps. Surprisingly, though, these two high-performance strategies don't seem to be real popular. As a performance engineer, my world has been covered up with a lot of chatty for the last 8 years.
But I'm not alone, being fan of the chunky -- consider Martin Fowler, who has written about ORM (object relational mapping) extensively. He also has two books on the 'most influential programmer book,' list. He was preaching chunky way back in 2003:
But I'm not alone, being fan of the chunky -- consider Martin Fowler, who has written about ORM (object relational mapping) extensively. He also has two books on the 'most influential programmer book,' list. He was preaching chunky way back in 2003:
"Try to pull back multiple rows at once. In particular,
never do repeated queries on the same table to get multiple rows."
...and others are adding to the chunky chorus ( here here here ). My post here focuses on the code, the data and the performance. Fowler did a similar comparison but focused on code style and where to put business logic. But Fowler's test was a bit extreme -- he worked with 1,000 db records to show the poor performance of chunky. These tests show the problem by selecting just 100 records.
But keep in mind that performance isn't everything:
But keep in mind that performance isn't everything:
"Any fool can write code that a computer can understand.
Good programmers write code that humans can understand."
Five Strategies
The throughput of five different implementations of the same XML-over-HTTP web service was tested. The web service is a simple account and transaction inquiry to the Postgres pgbench db.
The following graph shows throughput in red (tps / higher is better) and the strategy number in blue. See how the blue line rises like steps? The test ran each strategy for 1 minute, then moved on to the next larger strategy number: 1,2,3,4,5 and then it repeated 8 more times. Each request inquired upon 5 differnt accounts. In the graph below, strategy=scenario.

The requirements for the web service:
Given 1 to N account numbers, return transaction history and balance info
for all accounts. All 5 strategies must build the response data using
the exact same pojos and the same XML serialization code.
Stragey 1 has the fewest SQL invocations, 5 has the most (5 is a little extreme, actually), and 2, 3 and 4 line up inbetween (yes, in order).
| Tables | PGBENCH_ACCOUNTS | PGBENCH_HISTORY | Notes |
|---|---|---|---|
| Strategy_1 | 1 SELECT, OUTER JOIN to PGBENCH_HISTORY | The Chunkiest of the 5. Rarely seen in the wild | |
| Strategy_2 | 1 SELECT | 1 SELECT | Rarely seen in the wild |
| Strategy_3 | 1 SELECT | 1 SELECT per account | |
| Strategy_4 | 1 SELECT per account | 1 SELECT per account | |
| Strategy_5 | 1 SELECT per account | 1 SELECT PER account to retrieve unique IDs. 1 SELECT for each full history record. | The Chattiest of the 5. |
Validation
Any one interested in checking my facts in the table above? I know, you're busy, which is part of why production bound code/sql rarely gets a full vetting. Instead of guessing, let's just look at what happened with each strategy -- graphically -- using wuqiSpank.

SQL
The following are the SQL executed for one invocation of each strategy. The same account numbers (and all their corresponding history records) were used for each strategy.
Strategy 1:
A single query:
SELECT a.aid, a.bid, a.abalance, a.filler, h.tid, h.hid, h.delta, h.mtime,
h.filler FROM pgbench_accounts a LEFT OUTER JOIN pgbench_history h
ON a.aid = h.aid WHERE a.aid in (?,?,?,?,?) ORDER BY a.aid, h.mtime desc
Strategy 2:
2 queries:
SELECT a.aid, a.bid, a.abalance, a.filler FROM pgbench_accounts a
WHERE aid in (?,?,?,?,?)
SELECT tid , hid, bid , aid , delta , mtime , filler
FROM pgbench_history WHERE aid in (?,?,?,?,?) ORDER BY aid, hid
SELECT a.aid, a.bid, a.abalance, a.filler FROM pgbench_accounts a
WHERE aid in (?,?,?,?,?)
SELECT tid , hid, bid , aid , delta , mtime , filler
FROM pgbench_history WHERE aid in (?,?,?,?,?) ORDER BY aid, hid
Strategy 3:
6 queries:
( 1x) SELECT a.aid, a.bid, a.abalance, a.filler
FROM pgbench_accounts a WHERE aid in (?,?,?,?,?)
( 5x) SELECT tid, hid, bid, aid, delta, mtime, filler
from pgbench_history WHERE aid = ?
6 queries:
( 1x) SELECT a.aid, a.bid, a.abalance, a.filler
FROM pgbench_accounts a WHERE aid in (?,?,?,?,?)
( 5x) SELECT tid, hid, bid, aid, delta, mtime, filler
from pgbench_history WHERE aid = ?
Strategy 4:
The following two queries were retrieved 5 times each, for a total of 10 queries:
SELECT aid, bid, abalance, filler from pgbench_accounts WHERE aid = ?
SELECT tid, hid, bid, aid, delta, mtime, filler from pgbench_history
WHERE aid = ?
The following two queries were retrieved 5 times each, for a total of 10 queries:
SELECT aid, bid, abalance, filler from pgbench_accounts WHERE aid = ?
SELECT tid, hid, bid, aid, delta, mtime, filler from pgbench_history
WHERE aid = ?
Strategy 5:
The following 25 queries were executed 5 times for a total of about 125 queries.
( 1x) SELECT aid, bid, abalance, filler from pgbench_accounts WHERE aid = ?
(24x) SELECT hid from pgbench_history WHERE aid = ?
( 1x) SELECT aid, bid, abalance, filler from pgbench_accounts WHERE aid = ?
(24x) SELECT hid from pgbench_history WHERE aid = ?
Instructions
- Install PostGreSQL. I used 9.2
- Load pgbench sample data as detailed below.
- Add a seuquence / primary key to the pgbench_history table.
- Download the war file and unzipt it to a blank folder.
- Make sure the JDBC connection info is right in this file:
./src/main/webapp/META-INF/context.xml - Build it with
mvn clean package - Deploy target/sqlPerfAntiPatterns.war to Tomcat 7+
- Run the service using this URL:
localhost:8082/sqlPerfAntiPatterns/sqlPerfServlet?pgbenchScenarioNum=2&pgbenchAccountIds=34591,9483121,78941,111294,9122
The following populates the pgbench_accounts table, but not the pgbench_history table:
export DB_NAME=db_pgbench
export SCALE_FACTOR=100
export HOSTNAME=localhost
export PORT=5432
export USER=postgres
pgbench -i -s $SCALE_FACTOR -h $HOSTNAME -p $PORT -U $USER $DB_NAME
-- add primary key to history table
db_pgbench=# ALTER TABLE pgbench_history ADD COLUMN hid SERIAL PRIMARY KEY;
NOTICE: ALTER TABLE will create implicit sequence "pgbench_history_hid_seq" for serial column "pgbench_history.hid"
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "pgbench_history_pkey" for table "pgbench_history"
ALTER TABLE
--added index for searching history for account id's.
CREATE INDEX idx_aid on pgbench_history (aid);wuqiSpank
UPDATE: October 12, 2014. Check out http://wuqiSpank.org for the latest release of wuqiSpank.
Yep, that's the name of the monitoring application that I'm writing. wuqi. spank. wuqispank.
- Is your code SELECTing data from the exact same table multiple times in a single request?
- How many round trips does your code make to the database?
- Re-executing the exact same SELECT statement?
There are all kinds of performance efficiencies to be gained by refactoring this kind of code.
I'm working on a monitoring tool that will visually answer the above questions by graphing your applications' SQL activity. wuqi = woefully unnecessary query invocation. Spank those wuqi's.
Here are some of the milestones in writing this monitoring application:
- The first step is to get a headless monitoring API that will allow me to write java code that will get notified when SQL statements get executed on a remote JVM. InTrace is a great tool for tracing all JVM method invocations, but the GUI is very tightly integrated with the event API....until now: this headless version of the InTrace API let's you write monitoring tools to collect events from remote (or local) JVMs.
- What code of mine executed this particular SQL statement? To answer this question, wuqispank will need to have stacktrace information for all SQL statements. Need to be able to configure the InTrace agent to send back stacktraces for all (perhaps selected) method calls.
- All those stacktraces will take up a lot of bandwidth. This InTrace enhancement is a fork of the main InTrace repo. It adds GZIP compression to the network events transmitted over the wire.
- Need to write a web application that uses the headless InTrace API to graphically display SQL activity....
Subscribe to:
Posts (Atom)